It typically includes composing code to engage with a site's HTML and extract the preferred details. For instance, if you intended to extract a list of product names and rates from a shopping internet site, you might write a web scrape to do so. Our group of dedicated and dedicated professionals is a distinct mix of method, creativity, and innovation. Both scraping and crawling are information removal techniques that have been around for a long time. Depending on your company or the sort of solution you're aiming to obtain, you can opt for either of both. It's necessary to understand that while they may show up the same Transform your business with customized BI externally, the actions entailed are pretty various.
Benefits of Solid-state Drives RAID Arrays in Data Centers - Spiceworks News and Insights
Benefits of Solid-state Drives RAID Arrays in Data Centers.
Posted: Wed, 19 Apr 2023 07:00:00 GMT [source]
Information scratching, on the various other hand, is usually an one-time or periodic process. Data crawling, additionally referred to as web crawling or spidering, is the procedure of automatically accumulating data. Google Spreadsheets is usually a go-to option for busy organizations that locate the Web and team collaboration essential for their everyday procedures.
Information Entrance Outsourcing Boosts The Firm's Earnings
2 common methods made use of to accumulate information from the website are crawling and scratching data. Although the terms are typically made use of interchangeably, there are significant differences in between these two approaches. In this post, we'll explore the key differences in between information crawling and information scuffing. Data scraping is mostly used in artificial intelligence, equity research, and retail marketing.
So where are we all supposed to go now? - The Verge

So where are we all supposed to go now?.
Posted: Mon, 03 Jul 2023 07:00:00 GMT [source]
By choosing the appropriate approach based on their requirements, business can extract purposeful understandings and make informed decisions. In internet crawling, the emphasis is on indexing and collecting as much information as possible. In today's data-driven world, companies and organizations count on collecting and analyzing substantial amounts of data. That's right, you and your personnel can service a Google Sheet without a web link and expect the system to track and conserve modifications on the drive. Speaking of modifications, all edits individuals ever make in a document are saved and readily available for review. You can also share data with other individuals to save time on back-and-forth email communication and also transform Excel files into Google Sheets.
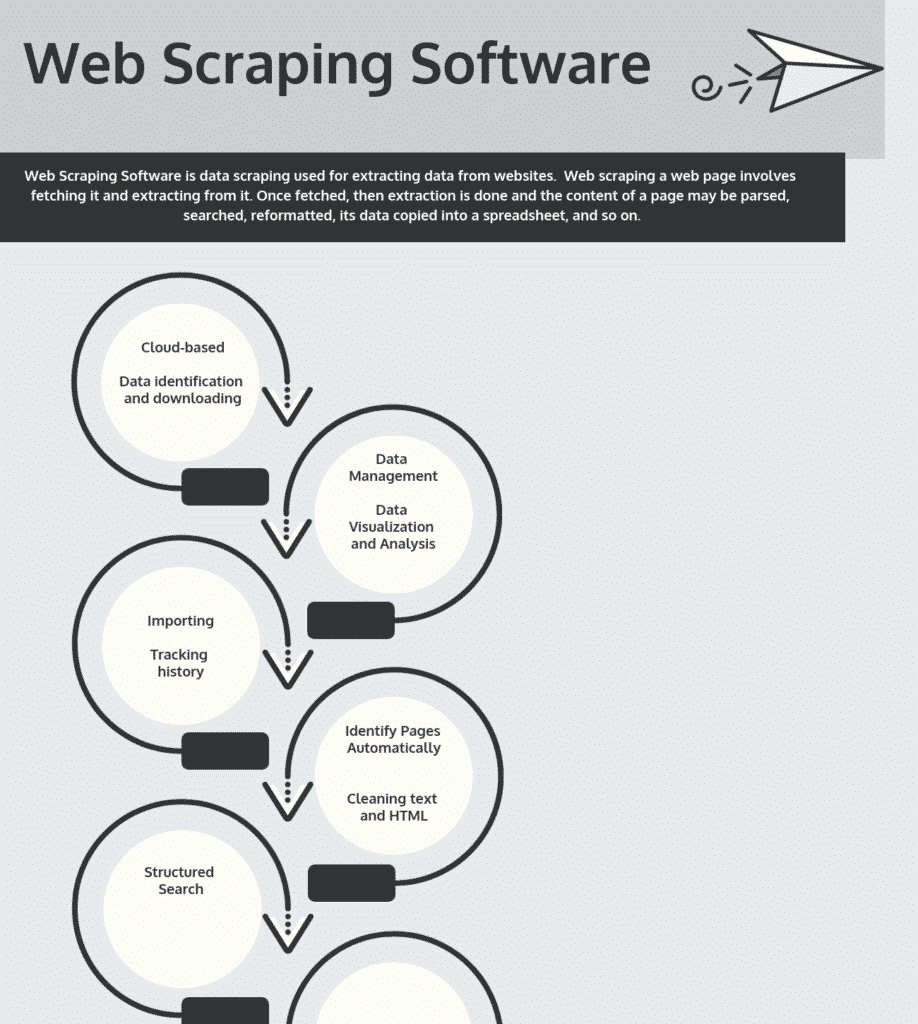
Find Out More About Internet Scuffing
This information may also consist of metadata for classification functions. Financial solutions generally utilize this to gather and examine user information. Is extra common today than manual "copy/paste." Nevertheless, by hand accumulating data from websites can still help smaller tasks. Nevertheless, they normally overlap-- so it's very easy to swap these terms. We configure, deploy and preserve work in our cloud to extract data with finest quality. Calls for a space to be minimized, bringing some costs to the users.
- They go deeper into an internet site than a hand-operated scan would permit due to the fact that they locate web links and pages that may not be noted in conveniently obtainable Custom BI implementation case studies locations of a website.
- In this article, we'll explore the vital distinctions in between information creeping and data scuffing.
- Additionally, you can play with shade and font styles to stress relevant chart information, highlight a row for contrasting worths, and show key points arising from the details.
- By automating http://angelocafu464.yousher.com/how-huge-allows-data-ways-to-uncover-the-significant-information the information collection process, companies can conserve time and sources while obtaining understandings that can aid them make better choices.
- While PDF is likewise helpful for saving audio data, it could not be the very best option for scuffing symbols.
When they locate sites that contain details relevant to a particular subject, the bot will certainly make a note of that website and provide it a ranking in an individual's search results page as necessary. Second, you might stop working to gather target information because some websites could have data blockades. This indicates data from internet sites ends up being rarely obtainable to crawlers. If youuse scrapes, you might be able to bypass this restriction. A scrape can provide you access to huge proxy networks that can enable you to gather web information making use of multiple IPs.